Ripping books from Internet Archive
The Internet Archive, also known as archive.org, is a non-profit digital library that aims to provide universal access to knowledge. It was founded in 1996 with the mission of preserving and providing access to historical collections in digital form and it continues to do so.
The Internet Archive also offers access to millions of books, movies, audio recordings, and other media through its Open Library project. It provides free access to a vast collection of digitized books, allowing users to borrow and read them online.
You can find various books on the Internet Archive free to download but there are certain books which can be accessed only after proper borrowing which requires an account on the website. The limitations are in place due to the legal issues with authors and publication houses etc.
The free books are easily downloadable with the direct download links available on the corresponding page. However, the books that are only accessible after borrowing have another downside – the download option is disabled for them.
To get around that limitation & obtain a portable copy of such books a downloader script helps immensely.
Setup
You need to have Python, pip & git installed on your machine. Clone the repository & navigate inside the directory on you local system by running:
git clone https://github.com/MiniGlome/Archive.org-Downloader.git
cd Archive.org-Downloader
Now that you are inside the script directory, install the dependencies (requests, tqdm and img2pdf) by running:
pip install -r requirements.txt
Usage
Create an account on archive.org if you don’t have one already & note down the email & password somwhere safe. Now to download a book from Internet Archive which have no direct download links provided or which is accessible only after borrowing, copy the URL of the book / page use the following format to rip the book:
python3 archive-org-downloader.py -e EMAIL -p PASSWORD -u BOOK-URL -r RESOLUTION
For example I found this title on archive.org which is only available for borrowing & I need the portable copy of it.
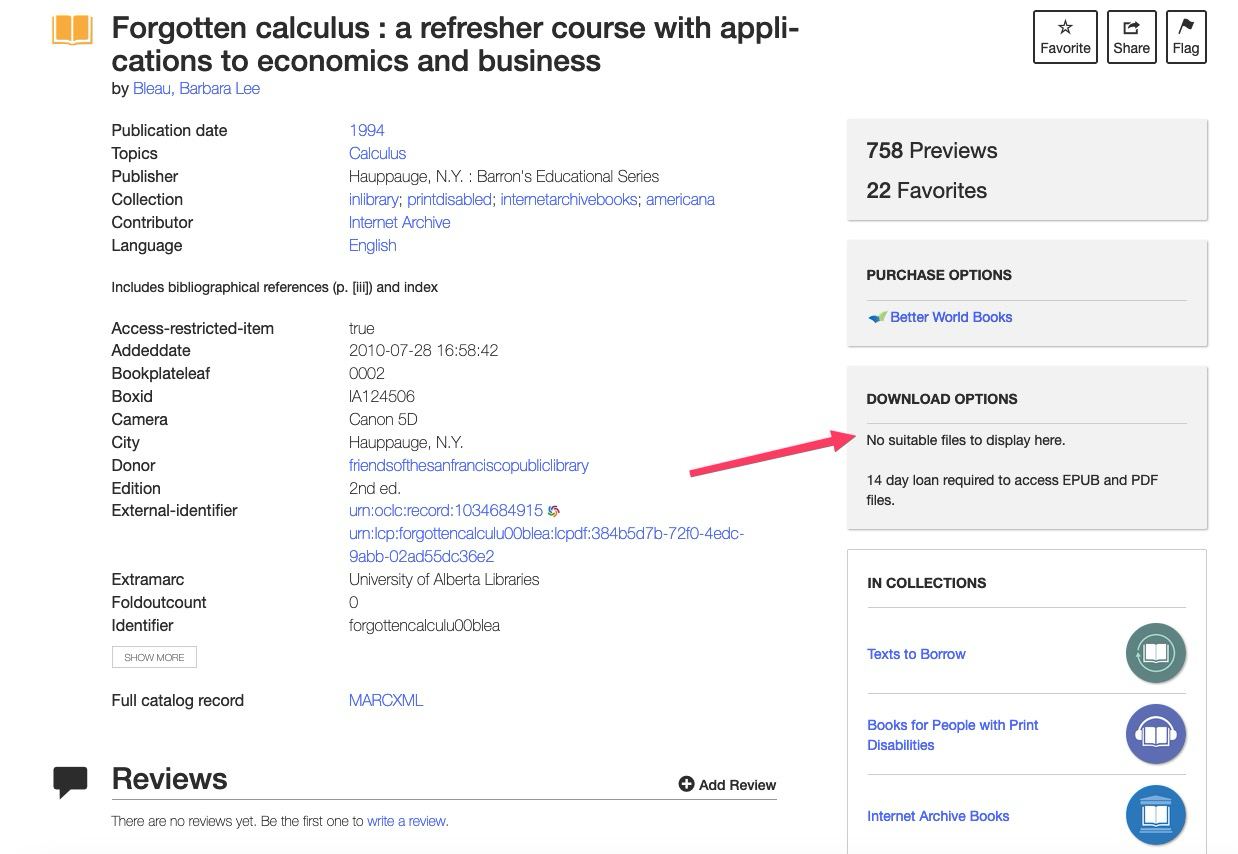
To download this book as pdf, I need URL of the book, email & password of my archive.org account and pass them as arguments in the following command:
python3 archive-org-downloader.py -e [email protected] -p 1ntern3t-arch1v3 -r 0 -u https://archive.org/details/forgottencalculu00blea/page/4/mode/2up
The -r is for resolution & 0 is best. The above command will download the book as pdf in my current directory.
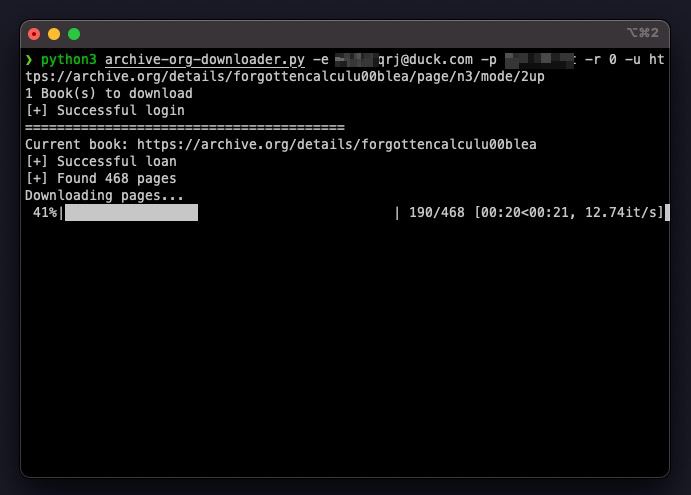
The script have another flag for bulk downloading. Like for example in case of mass downloading multiple books, put the urls into a single .txt file with line breaks and instead of -u argument pass -f with the path/to/file.txt argument.
Closing Thoughts
This script is very useful for ripping restricted books from Internet Archive. To ease the overall process I created a GUI version of it for MacOS specifically. If you want instructions on that or if you want the binary feel free to reach out. I will be more than glad to share the App.
Reply via [mail](mailto:[email protected]?subject=📝 Response to blog post)
